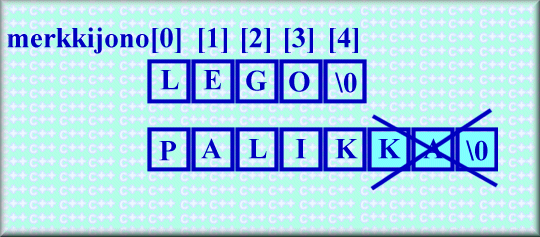
Perusteet
Asiaan
Sitten suoraan asiaan ja ensimmäiseen C++-ohjelman esimerkkiin:
#include <iostream.h>
void main()
{
cout << "Hello world!";
}
Kyseessä on äärettömän klassinen ohjelma. Se tulostaa ruudulle "Hello world!" Ruvetaanpa tutkimaan ohjelmaa hieman syvällisemmin.
Ensimmäisella rivillä käytetään esikääntäjän (preprocessor) käskyä. Sen erottaa #-merkistä alussa. Esikääntäjä on ohjelma, joka käsittelee lähdekoodin #-alkuiset kohdat ennen kuin oikea kääntäjä pääsee siihen käsiksi. Kääntäjistä ja kääntämisestä kerroin Yleistä-osiossa.
Include on englantia ja tarkoittaa sisällytä. Ja nerokkaasti C++:ssa sillä on sama tarkoitus. #include <iostream.h> nimittäin sisällyttää iostream.h nimisen tiedoston tuolla kohdalle. Eli aito kääntäjä (compiler) saa tiedoston sellaisena, että #include <iostream.h> tilalla on tiedoston iostream.h sisältö.
iostream.h sisältää tulostukseen ja syöttöön liittyviä toimintoja, kuten cout. C++:ssä on vain parikymmentä käskyä, koska lähes kaikki tapahtuu näiden otsikkotiedostojen (.h) sisältämien toimintojen avulla. Sisällyttämällä poimitaan ne toiminnot, mitä kussakin ohjelmassa tarvitaan.
Sitten seuraavalle riville. Siellä lukee:
void main()
Tässä määritellään pääfunktio. Jokaisessa C++-ohjelmassa pitää olla main()-osio. void tarkoittaa että main() osa ei palauta arvoa, mistä meidän ei vielä tarvitse välittää sen enemmän kuin suluistakaan. (Olen saanut melko paljon kritiikkiä tässä esitellystä tavasta määritellä main(). Tässä esitetty tapa on kuitenkin aivan oikea, tosin "oikeissa" ohjelmissa olisi kiltti tapa palauttaa paluuarvo. Tätä kysymystä käsittelenkin myöhemmin Funktio-osiossa.)
Sitten eteenpäin. {-merkki aloittaa main()-osion, josta löytyykin vanha tuttu, cout. cout on olio (object), josta sinun ei tarvitse myöskään välittää vähään aikaan. Sinun tarvitsee tietää vain, että coutia käytetään tekstin tulostamiseen. coutin jälkeen tulevat <<- ohjausmerkit ja haluttu teksti lainausmerkeissä.
Jokaisen ohjelmarivin C++:ssa päättää ;-merkki, jonka unohtaminen voi aiheuttaa todella kummallisia virheitä. Kannattaa siis olla tarkkana: jos kääntäjä valittaa jostain rivistä, josta et löydä mitään virhettä, kannattaa tarkistaa onko edellisiltä riveiltä jäänyt uupumaan ;-merkki.
Lopuksi vielä päätetään main()-osio toisin päin olevalla aaltosululla, eli }-merkillä. Sitäkään ei tule unohtaa.
Siinäpä se.
Syöttö ja tulostus
Ohjelma, joka pelkästään tulostaa kaikenlaisia rivouksia ruutuun käy pitemmän päälle hieman köyhäksi, joten otetaanpa sitten jotain muuta mukavaa mukaan. Eli esimerkin voimin taas:
#include <iostream.h>
void main()
{
int luku;
cout << "Anna luku" << endl;
cin >> luku;
cout << "Pöh, ei " << luku << " nyt mitenkään kummoinen ole.";
}
int luku; asti kaiken pitäisi olla pässinlihaa. Mutta sitten alkaa tapahtua, pidä laidoista kiinni!
Ensin luodaan int-tyyppinen muuttuja (variable). Tyypeistä sitten myöhemmin. (äsh, tälle pitää kehittä joku lyhenne. Vaikka TSM, Tästä Sitten Myöhemmin. OK?) int-tyyppinen muuttuja pystyy tallentamaan yhden kokonaisluvun. Muuttujia käytetään jonkin tiedon säilömiseen. Käytännössä ne ovat vain kohtia muistista, joille on annettu inhimillisempi nimi.
Seuraavana tuleva cout on olio - hetkonen, mikä himputti on olio? No, se selviää kun on sen aika. cout on siis.. härveli, jolla tulostetaan tavaraa ruudulle. Sitten mukaan tulee coutin kaveri, cin. Se toimii coutin vastaparina: kun cout tulostaa, cin lukee. Tässä tapauksessa luetaan luku-muuttujaan. Sitten vielä sen arvo tulostetaan. Muuttujat pitää erottaa tekstistä <<-merkein ja teksti pitää ympäröidä lainausmerkein. Lopussa on endl, joka tarkoittaa end line. Eli siinä tulee rivinvaihto. Tekstit, muuttujat ja endl:n tyyliset ohjauskäskyt pitää erottaa toisistaan <<-merkein.
Jos olet ollut tarkkana, olet ehkä huomannut että cinin nuolet osoittavatkin toiseen suuntaan. Nuolien suunta on helppo muistaa siitä, että ne osoittavat aina siihen suuntaan mihin tieto kulkee. Eli coutissa tieto kulkee näyttöön, jota tässä edustaa cout, ja tällöin nuolet ovat coutin suuntaan. cinissa taas tieto kulkee muuttujaan, jolloin nuolet osoittavat muuttujaan päin.
Muuttujat
Nyt sitten niistä kauan kaivatuista muuttujista ja tyypeistä. Jotta muuttujaa voidaan käyttää, pitää se määritellä. Jotain alkeellista Basicin versiota aiemmin käyttäneestä se voi tuntua vähän hankalalta, mutta on itseasiassa todella hyvä asia, koska näin ei pääse vahingossa käyttämään olematonta muuttujaa. Muuttuja määritellään näin:
tyyppi nimi;
Eli tyyppi kertoo minkä tyyppistä tietoa muuttuja sisältää (TSM, Tästä Sitten Myöhemmin) ja nimi minkä niminen muuttuja on. Yleensä muuttuja kannattaa alustaa (initialise) jollakin arvolla luonnin yhteydessä. Niinpä luomme tässä ika-nimisen kokonaisluvun sisältävän muuttujan ja laitamme siihen arvon 0.
int ika = 0;
Alustaminen on todella tärkeää: jos muuttujaa ei alusteta, siinä voi olla mitä tahansa roskaa. Nimeksi kelpaa mikä tahansa yhteen kirjoitettu tekstipötkö, kunhan se ei sisällä ääkkösiä, ei ala numerolla ja ei ole varattu sana. Varattu sana tarkoittaa C++-kielessä sanaa, jolla on jo jokin erityinen merkitys ohjelmointikielessä. Eli varattu sana on "komento". Lista varatuista sanoista löytyy Sekalaista-kohdasta. Nimi saa sisältää numeroita, mutta ei saa alkaa numerolla. Myös alaviivaa (_) saa käyttää vaikka nimen alussa. Tosin ihan nimen alkuun en laittaisi alaviivaa, koska muuttuja helposti sekottuisi joihinkin kääntäjän muuttujiin, jotka alkavat myös alaviivalla. Ja vielä yritän syövyttää tätä aivokudoksiisi: pieni ja iso kirjain ovat eri asia - muuttujat painekattila, paineKattila, PaineKattila ja PAINEKATTILA ovat kaikki eri muuttujia.
Sitten ne tyypit:
int kokonaisluku char merkki(kirjain) float desimaaliluku double pidempi desimaaliluku
Sitten osaa näistä tyypeistä voi vielä ryydittää etuliitteillä:
long suurempi luku short pienempi luku unsigned etumerkitön(voi siis olla vain positiivinen)
..ja vielä pari muuta joista sinun ei tarvitse välittää.
Eli lopulta saamme tämmöisen listan:
| Tyyppi | Koko(tavuina) | Arvoalue |
| int | 2 | -32768..32767 |
| unsigned int | 2 | 0..65535 |
| short int | 2 | -32768..32767 |
| unsigned short int | 2 | 0..65535 |
| long int | 4 | -2147483648..2147483647 |
| unsigned long int | 4 | 0..4294967295 |
| char | 1 | -128..128 (ASCII-merkit) |
| unsigned char | 1 | 0..255 (ASCII-merkit) |
| float | 4 | 1.2e-38..3.4e38 |
| double | 8 | 2.2e-308..1.8e308 |
| bool | tosi tai epätosi |
Muuttujien arvoalueet vaihtelevat kääntäjittäin. Tai oikeastaan lähinnä int-tyypin arvot vaihtelevat. Vanhemmissa PC:n real mode -kääntäjissä int on 2 tavua, mutta uudemmissa protected mode -kääntäjissä 4 tavua. Tällöin long int ja int ovat saman kokoisia. short int on kuitenkin kaksi tavua. Ainakin DJGPP:ssä on myös erikoisempi tyyppi long long int, joka on 128-bittiä eli 16 tavua.
Kun ajatellaan näitä tietotekniikan peruskäsitteitä, eli bittejä (bit), tavuja (byte) ja sanoja (word) (jälkimmäinen ei kyllä ole ihan peruskäsite, mutta olet ehkä kuullut sen), niin unsigned char vastaisi tavua, joka koostuu 8 bitistä. 2-tavuinen int olisi sana ja long int kaksoissana (double word).
Yksittäistä bittiä lähimpänä on bool-tyyppi (Boolen totuusarvo). Sitä ei alunperin C++-kielessä ollut ja niinpä kaikki kääntäjät eivät sitä välttämättä tue. bool-muuttujan arvo voi olla tosi tai epätosi, siis sillä voi esimerkiksi kertoa onko hiiren nappi pohjassa. bool-tyypin esittämiseen käytetään yleensä enemmän kuin yksi bitti tilaa, koska kokonaisten tavujen käsittely on nopeampaa - tämä on kääntäjäkohtaista. Tietokoneen bitteihin pääsee konkreettisestikin käsiksi käyttämällä binäärioperaattoreita, jotka esitellään myöhemmin.
Otetaanpa nämä muuttujat nyt käyttöön:
#include <iostream.h>
void main()
{
int luku1, luku2, tulos;
luku1 = luku2 = tulos = 0;
cout << endl << "Anna ensimmäinen luku:";
cin >> luku1;
cout << endl << "Anna toinen luku:";
cin >> luku2;
tulos = luku1 + luku2;
cout << "Tulos on " << tulos;
}
Noin. Kuten huomaat, voidaan saman tyyppiset muuttujat määritellä pötkössä pilkulla erottaen. Seuraavalla rivillä on kätevä tapa alustaa monta muuttujaa yhdellä kertaa. Sitten kysytään kaksi lukua, jotka tallennetaan luku1- ja luku2-muuttujiin, lasketaan ne yhteen (TSM) ja sijoitetaan tulos tulos-muuttujaan. Lopuksi vielä tulos-muuttujan arvo tulostetaan.
Liukuluvut ja lukujen merkitseminen
Lukuja merkitessä voi käyttää tällaisia kirjainlyhenteitä (ekassa sarakkeessa olevat symbolit ovat vaihtoehtoisia, siis vain yhtä niistä käytetään):
| l L | loppuliite | Kokonaisluku (long) |
| u U | loppuliite | Etumerkitön kokonaisluku (unsigned) |
| f F | loppuliite | Reaaliluku (float) |
| l L | loppuliite | Reaaliluku (long double) |
| O | etuliite | Oktaaliluku |
| 0x 0X | etuliite | Heksaluku |
| e E | välissä | Reaaliluvun kymmenpotenssimuoto |
Kaikkea tuosta ei tarvitse ymmärtää. Selittelen kuitenkin jotakin. Ensinnäkin liukuluvut (floating point number). Mitä ne ovat? Hirveän syvällisesti emme voi ruotia liukulukuja, siis muuttujatyyppejä float, double ja long double, tässä yhteydessä. Mikäli olet opiskellut jonkin verran fysiikkaa tai vastaavaa luonnontiedettä, niin varmaan tämän tyylinen merkintä on tullut sinulle tutuksi: 1.245 * 10³, siis 1.245 kertaa kymmenen potenssiin kolme. Idea on, että alkuosa ilmoittaa itse arvon ja loppuosa suuruusluokan. Esimerkkinä kilometri: kilo tarkoittaa tuhatta, siis tuhat metriä. Kolme kilometriä olisi: 3 * 10³ m=3 * 1000 m=3000m. Kymmenen potenssi voi olla myös negatiivinen; milli on tuhannesosa ja kolme millimetriä on 3 * 10^-3. Merkintä "^-3" tarkoittaa potenssiin miinus kolme, tuota potenssia kun ei ole valmiina symbolina. Liukuluvuissa on ihan sama idea, mutta nyt kun kyseessä ovat bitit, niin pelaamme kahden potensseilla. Eli liukuluvut voivat esittää hyvinkin suuria summia, mutta tarkkuus kärsii.
Jos haluat ohjelmoidessa käyttää kymmenpotensseihin perustuvaa merkintätapaa, niin se käy näin: 1e1, siis kymmenen potenssi tulee e:n (eksponentti) perään. Esimerkiksi luku miljardi on järkevämpi kirjoittaa 1e9 kuin 1000000000. Elektronin paino levossa on noin 9.11e-31 kg, siis 0.000000000000000000000000000000911 kg. Kumpi tapa on kätevämpi?
Monesti rautatasolla kikkailtaessa (eli ohjelmoidessa koodia, joka käsittelee tietokoneen laitteistoa) heksalukujen käyttäminen on paljon kätevämpää. Jos et tiedä mitä heksaluvut ovat, niin hyppää tämä yli (idea heksaluvuissa on kuusitoistakantaisuus; kun normaalit luvut perustuvat kymmenen potensseihin, ovat siis muotoa a * 10^0 + b * 10^1 + c * 10^2 jne.. niin heksaluvuilla kymmenen paikalla on kuusitoista) Nolla-äks alussa merkitsee heksaluku, siis vaikka 0x22 tulkitaan 2*16 + 2=34. Oktaaliluvut ovat samaa sarjaa, kantaluku on vaan kahdeksan.
Yllä olevan taulukon muut lukuliitteet (neljä ensimmäistä) kertovat kääntäjälle, minkä tyyppinen joku kirjoitettu luku on. Harvoin niitä kyllä oikeasti tarvitsee. Kääntäjä olettaa kaikki luvut int-tyyppisiksi tai jos niissä on desimaalipiste (tai ovat eksponenttimuotoisia, esim 1e1) niin tyypiksi räimäistään double. Ja sillä pärjää jo hyvin pitkälle.
Vielä käännä silmiäsi vähän takapakkia edelliseen kappaleeseen. Mitäs siellä roilotellaan: desimaalipiste? Siis mikä piste, pilkullahan desimaalit erotellaan... Mutta niin ei ole Ameriikoissa ja muissa hienoissa paikoissa, joissa C-kielen syntysanat on loitsittu. Niinpä erotin on yhä piste ja sillä selvä. Vastaan ei auta vängätä. Piste.
Tyyppimuunnos
Joskus sitä tulee tarvetta muuntaa muuttujaa tai tietoa tyypistä toiseen. No, sehän sopii. Tyyppimuunnosta (typecasting) käytetään laittamalla haluttu tyyppi sulkuihin. Jos siis haluat vaikka sijoittaa double-arvon int-muuttujaan, käy se näin: int i=(int)doubleMuuttuja;
Kun desimaaliosan sisältävä muuttuja muutetaan kokonaislukumuuttujaksi, tehdään se katkaisemalla (truncate). Siis desimaalipilkun jälkeiset numerot heitetään mäkeen. Jos arvo halutaan kuitenkin oikeaoppisesti, pitää se pyöristää. Kätevästi se onnistuu lisäämällä muuttujaan 0.5 ennen muunnosta. Jos muuttuja on negatiivinen, pitää silloin vähentää. Esim. 3.2 + 0.5=3.7 -> 3 tai 3.6 + 0.5=4.1 -> 4 tai -2.6 - 0.5=-3.1 -> -3.
Jos muuttuja on liian suuri haluttuun arvoon, se pyörähtää ympäri. Esimerkiksi unsigned char muuttujan arvoalue on 0..255. Jos siihen sijoitetaan luku 260, pyörähtää muuttuja ympäri ja saa arvon 260 - 256 = 4.
double d = 3.487: int i; if (d > 0) i = (int)(d + 0.5); // "pyöristys" else i = (int)(d - 0.5);
Asetuksista ja kääntäjästä riippuen onnistuvat jotkut tyyppimuunnokset myös ilman suluilla ilmoitettua muunnosoperaatiota. Hyvään ohjelmointitapaan kuuluu kuitenkin aina erikseen kertoa että nyt muunnetaan tietoa tyypistä toiseen. Näin ohjelmista tulee helppolukuisempia ja virheiden tekeminen ei ole ihan niin helppoa.
Tuon esimerkin ymmärtäminen voi aiheuttaa vähän ongelmia, mutta ei hätää. Lue lisää niin opit. En vaan osaa keksiä mihin minä tämän tyyppimuunnosjutun muuallekaan lykkäisin, joten laitoin sen tähän. Pari kappaletta vielä ja kaikki selkenee.
Taulukot
Sitten siirrymmekin vähän järeämpiin muuttujiin eli taulukoihin (array). Kuvitellaan että haluat luoda muuttujan, joka kuvaa jätkänshakin pelialuetta. Tietenkin voisi luoda 9 erillistä muuttujaan, mutta on kätevämpää käyttää taulukoita. Taulukko luodaan näin:
alkioiden_tyyppi taulukonNimi[eka_ulottovuus][toka ulottuvuus jne..];
Eli jotta saisimme jätkänshakkialuetta (3x3) vastaavan int taulukon, teemme näin:
int peliAlue[3][3];
Taulukko koostuu alkioista (3x3 taulukossa niitä on 9) ja taulukon nimen edessä oleva tyyppi määrää minkä tyyppisiä alkiot ovat.
Taulukko voidaan alustaa luonnin yhteydessä - siis siihen voidaan tunkea matskua kun se määritellään. Se tehdään yhtäsuuruusoperaattorilla, kirjoittamalla arvot kaarisulkeiden sisään:
int taulukko[5]={0, 1, 2, 3, 4};
Jos taulukko alustetaan näin, sen kokoa ei tarvitse antaa - osaahan kääntäjäkin laskea. Myös moniulotteinen taulukko voidaan alustaa tähän tyyliin, tosin silloin koko tulee antaa, koska kääntäjä ei voi päätellä sitä itse. Arvot pitää luetella niin, että ensin käydään viimeisen (oikeanpuoleisen) ulottuvuuden arvot läpi. Siis jos ajatellaan, että ensimmäinen ulottuvuus on rivit ja toinen sarakkeet, niin ensin laitetaan ensimmäisen rivin kaikki arvot, sitten toisen jne.. Jospa alla oleva esimerkki olisi havainnollisempi. Arvoja voidaan ryhmitellä hakasulkein esityksen selventämiseksi.
#include <iostream.h>
void main()
{
//int taulukko[2][3] = {1, 2, 3, 4, 5, 6};
int taulukko[2][3] = { {1, 2, 3},
{4, 5, 6} };
cout << taulukko[0][0] << " " << taulukko[0][1] << " " << taulukko[0][2] << endl;
cout << taulukko[1][0] << " " << taulukko[1][1] << " " << taulukko[1][2] << endl;
}
Ohjelmaa tulostaa:
1 2 3 4 5 6
Alustuksesta on esitetty kaksi täysin saman asian tekevää versiota. Toinen on tietenkin kommentoitu pois, ettei kääntäjä murahtelisi. Kuten siis huomaat, ensin tulevat ensimmäisen rivin arvot [0][0], [0][1] ja [0][2], sitten toisen rivin arvot.
Oletkin jo ehkä odottanut ohjelmaa, joka kysyy nimen ja sanoo "Terve, <nimi>". Nyt sellainen tulee, ja koska C++:ssä ei ole omaa tyyppiään merkkijonoille, käytämme merkkitaulukkoa.
#include <iostream.h>
void main()
{
cout << "Mikä on nimesi? ";
char nimi[20];
cin >> nimi;
cout << endl <<"Jaa, että " << nimi << ". Vihje vanhemmilta, vai?";
}
Nimi-merkkitaulukko määritellään ja sille annetaan kokoa 20-alkiota, eli siihen mahtuu enintään 20-merkkiä (joten Laura Jenna Ellinoora Alexandra Camilla Jurvanen ei mahdu). Kun on painettu enteriä, cin lopettaa lukemisen ja laittaa annetun nimen taulukkoon. Myös merkkijonotaulukko voidaan alustaa suoraan. Silloin käytetään lainausmerkkejä. Kokoa ei tarvitse antaa, kääntäjä määrittää sen ja lisää myös nollatavun (nollatavun? lue eteenpäin...), sekä ottaa sen huomioon kokoa laskiessa. On se luksusta...
#include <iostream.h>
void main()
{
char* nimi = "Oiva Apu";
cout << nimi << endl;
if (nimi[8] == '\0') cout << "Nollatavu se on, peeveli vieköön!";
}
Merkkitaulukot eli merkkijonot (string) ovat jäänne C:stä, C++:ssa yleensä käytetäänkin merkkijonoluokkia. Mutta se ei toki ole mikään tekosyy sille, etteikö merkkijonoja pitäisi osata. Merkkitaulukko toimii itseasiassa näin: kun määrittelemme taulukko[20], kääntäjä varaa 20 merkin verran muistia (muistin varaaminen tarkoittaa sitä, että alue merkitään käytetyksi eikä mikään muu muuttuja voi käyttää sitä) ja laittaa taulukon osoittaamaan jonon ekaan alkioon. Osoittaminen ja osoitinmuuttujat kuuluvat taas kategoriaan TSM. Kun haluamme merkin taulukko[5], ohjelman menee taulukon osoittamaan kohtaan muistia ja siirtyy siitä viiden merkin viemän tilan verran eteenpäin, ja sitten lukee merkin siltä kohden. Kun käsittelemme koko jonoa, meidän pitää tietenkin tietää missä se päättyy. Niinpä merkkijonot ovat nollatavuun päättyviä (NULL terminated), eli niiden viimeisenä merkkinä on '\n' eli '\0' eli NULL (nolla). Koska nollatavu vie yhden merkin verran tilaa, pitää merkkitaulukko aina tehdä yhtä isommaksi kuin todellista tarvetta on.
Alla olevassa kuvassa on esitetty, mitä muistissa tapahtuu kun taulukkoon char merkkijono[5] sijoitetaan sanat LEGO ja PALIKKA. PALIKKA\n on kolme merkkiä liian pitkä varattuun tilaan, joten se sotkee kolme tavua muistia. Seuraus voi olla melkein mitä vaan, mutta ei kuitenkaan mitään kovin positiivista.
Kuinka mokata taulukoiden kanssa
Lyön munuaiseni vetoa, että teet ainakin kerran elämässäsi tämän virheen: viittaat taulukko[1] luullen, että tuo osoittaa taulukon ekaan alkioon. Mutta niinpäs ei olekaan. Nimittäin C++ aloittaa taulukon alkiot jo nollasta. Eli taulukossa jono[3] on alkiot 0, 1 ja 2. Se tuntuu aluksi pöljältä, mutta kyllä siihen tottuu. Tilanne on sama kuin englantilaisten kerrostalojen kanssa: siellä saarivaltiossahan ja monissa muissa Euroopan maissa kerros yksi ei suinkaan ole maanpinnalla, vaan se kerros minkä me miellämme toiseksi kerrokseksi. Ohjelmoinnin harrastajalle tuo tuntuu kyllä hyvin fiksulta ratkaisulta. Myöhemmin tälle ratkaisulle esitetään myös hieman teknisempi selitys.
sizeof ja muuttujat
Muuttujien arvoalueet vaihtelevat, koska niiden koko muistissa on erilainen. Muuttujien todellinen muistinkulutus vaihtelee hieman ympäristöstä toiseen, joten ei kannata olettaa mitään muuttujien kokoon liittyvää. Esimerkiksi jos käytät nopeaa memcpy(..) -funktiota (TSM) muistialueiden kopiointiin, tulee muuttujien viemän tilan laskeminen eteen. memcpy(..) ottaa parametreikseen kohteen, lähteen ja kopioitavien tavujen määrän. Jos haluat kopioida 200 int-lukua taulukosta 1 taulukkoon 2, tapahtuu se näin:
memcpy( taulukko2, taulukko1, 200 * sizeof(int) );
Ensin on kohde (!), sitten lähde. Sitten tulee kopioitava määrä tavuina. Mikäli olisimme katsoneet tässä kappaleesta olevasta taulukosta, että: "Jaahas. int näyttäis olevan 2 tavua, joten lykätään siihen sitten 200*2.." niin ohjelma olisi toiminut noin 20%:ssa ympäristöistä. int voi olla, ja yleensä onkin, 4 tavua, jolloin 2 tavuisen intin olettaminen veisi ojasta allikkoon tai johonkin vielä kauheampaan paikkaan. Tämä sääntö syövytä neitseellisiin aivokudoksiisi, joita eivät vielä maallisen huolimattoman ohjelmoinnin siveettömyydet ole tahranneet: oleta niin vähän kuin mahdollista. C++:ssa on operaattori, jolla saadaan selville jonkun tietotyypin koko: sizeof. sizeof(int) tai sizeof int kertoo muuttujan koon. Alla olevassa ohjelmassa selvitellään eri muuttajatyyppien kokoja. long double -tyyppi ei ole aivan standardi ja monissa ympäristöissä se onkin samankokoinen kuin pelkkä double. Jotkin kääntäjät voivat yskiä bool-tyypistä, joten sen rivin voi joutua ottamaan pois.
#include <iostream.h>
void main()
{
cout << "sizeof(short int) " << sizeof(short int) << endl;
cout << "sizeof(int) " << sizeof(int) << endl;
cout << "sizeof(long int) " << sizeof(long int) << endl;
cout << endl;
cout << "sizeof(char) " << sizeof(char) << endl;
cout << endl;
cout << "sizeof(float) " << sizeof(float) << endl;
cout << "sizeof(double) " << sizeof(double) << endl;
cout << "sizeof(long double) " << sizeof(long double) << endl;
cout << "sizeof(bool)" << sizeof(bool) << endl;
}
Kommentoiminen
C++:aa on haukuttu maailman ainoaksi write-only (vain kirjoitettava) kieleksi. Sitä se helposti onkin ellei pidä mielessä muutamia juttuja. Kerron nyt aluksi kommentoinnista ja muita kikkoja sitten vähän myöhemmin.
Vaikka C++ onkin ohjelmointikieli, se on silti aika kaukana ihmiskielestä. Monesti onkin hyvä sotkea mukaan suomeksi tai savoksi kirjoitettuja kommentteja koodin toiminnasta kyseisessä kohdassa. C++:ssa on siihen kaksi tapaa:
// Kätevä yhden rivin kommentti. (C++-tyyliä)
/* tällainen C-tyylinen kommentti voi olla monta riviä pitkä */
Eli // aloittaa kommenttirivin ja /*..*/ merkein voi rajata kommenttialueen (voi käyttää myös koodin kommentoimiseen väliaikaisesti pois - tosin ei hirveän hyvin sovi siihen, koska koodin seassa olevat muut kommentoinnit ja merkit voivat sotkea).
Kommentointi on hyvä tapa, mutta rajansa kaikella. Einstein on sanonut, että hyvä teoria on vain niin monimutkainen kuin on välttämätöntä. Sama pätee kommentointiin: hyvä ohjelmoija kommentoi vain juuri sen verran kuin on välttämätöntä. Kommentointi on tärkeää, mutta löysäleukainen lavertelu ja itsestäänselvyyksien raapustelu vain hankaloittaa ohjelman lukemista ja syö arvoa seassa olevilta hyödyllisiltä kommenteilta.
Huono ohjelma ei muutu hyväksi kommentoimalla. Mikäli haluat viestiä jotakin ohjelman toiminnasta, pyri tekemään se ohjelman rakenteella ja muuttujien järkevällä nimeämisellä. Vain sellainen jota ei voi sanoa C++:n avulla kannattaa kirjoittaa kommenteiksi.